
I know that some are always suspicious of opening links but I have to say this link you have provided is worth putting that suspicion aside. I am particularly drawn to the following:
1. The authors compare AKD1000 & Loihi 2 with the Nvidia A100 PCIE 4.0 Dual Slot priced at $16,000.00 and produce the following numbers for AKD1000 compared directly with the A100 GPU:"On-chip Execution
Results for ANN vs. BrainChip SNN size, power, and speed are summarized in Table 6. Power consumption was ~1 W. GPU power was estimated at 30 W, using 10% of an NVIDIA A100’s maximum power consumption. Speed was slower for neuromorphic chips. GPU models could operate with much higher throughput due to batch processing, which might not be available for streaming cybersecurity data.
Table 6. ANN vs. BrainChip SNN Size, Power, and Speed
2. The concluding paragraphs confirming state of the art accuracy for both AKD1000 and Loihi 2 and full marks on the COTS SWAP criteria:"BrainChip Neuromorphic Platform
The following results are presented in this section: an improved data scaling process, an improved ANN to SNN conversion process, and running the converted model on a chip rather than just via software simulator. This gained valuable insights into real hardware inference speeds and power costs.
Data Scaling
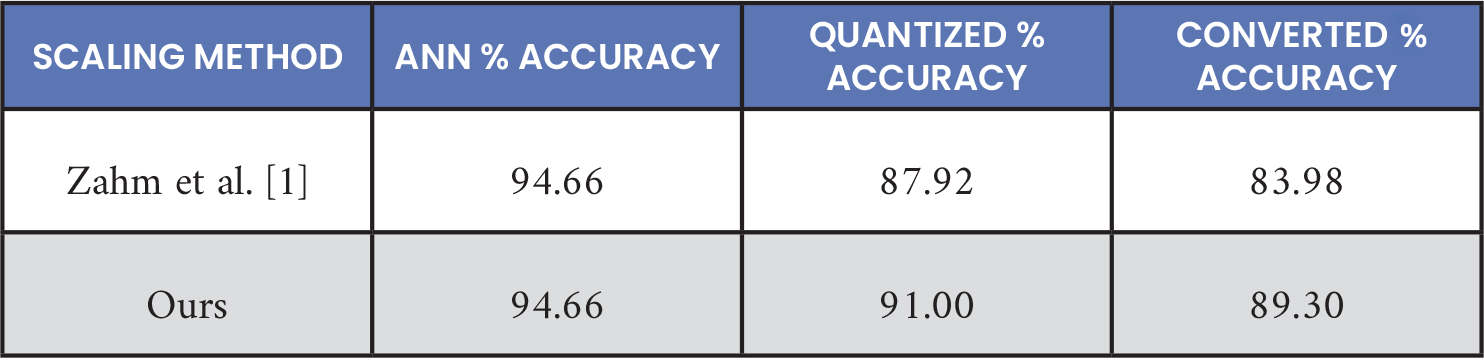
The new data scaling method outperformed the old Zahm et al. [1] method on both quantized and converted SNN models, as shown in Table 4. Quantized model performance improved ~3.1% and converted SNN model performance improved ~5.3%. Log-scaling was also tried but did not perform as well as the new method. The reduced accuracy drop was noted when converting the quantized model to an SNN with the data scaled via the new processes (3.9% vs. 1.7%). Passing scaling factors were also introduced to the SNN model in hardware to further reduce this accuracy loss when converting a quantized model. However, this was not used to produce Table 4, as Zahm et al. [1] used this technique. Data scaling experiments were done for SNN training but not ANN training, hence identical ANN performance. Note that identical initial ANN model and identical quantization retraining schedules were used and not the optimal ANN design and optimal quantization retraining schedules.
Table 4. BrainChip, SNN Data Scaling Technique vs. Performance
ANN to SNN Conversion
In Table 5, quantization yields dramatically smaller models to fit on low SWaP-C neuromorphic hardware. Accuracy increased for the ANN and SNN models, and ANN performance increased 4.7%. At 98.4% accuracy, this was similar to the state of the art presented in Gad et al. [2] and Sarhan et al. [3]. Improvements to the quantization schedule reduced the accuracy drop from 11.2% to 7.2% between full and reduced precision models.
Table 5. BrainChip, Accuracy Benchmarks
On-chip Execution
Results for ANN vs. BrainChip SNN size, power, and speed are summarized in Table 6. Power consumption was ~1 W. GPU power was estimated at 30 W, using 10% of an NVIDIA A100’s maximum power consumption. Speed was slower for neuromorphic chips. GPU models could operate with much higher throughput due to batch processing, which might not be available for streaming cybersecurity data.
Table 6. ANN vs. BrainChip SNN Size, Power, and Speed
Intel Neuromorphic Platform
Batch size was negatively correlated with accuracy, while learning rate was positively correlated with accuracy. Larger batch sizes took longer to converge but were less susceptible to random fluctuations in the dataset. The Bootstrap framework appeared to perform better with larger learning rates, whereas ANNs typically preferred smaller learning rates.
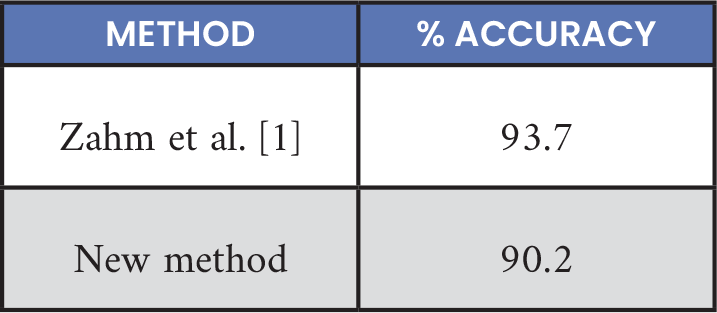
A final accuracy of 90.2% was achieved with the Lava DL Bootstrap framework, with an identical architecture to the Akida network, as shown in Table 7. This was a reduction in accuracy of 3.5% compared to the prior work of Zahm et al. [1]. However, the old SNN-Toolbox performed direct ANN-SNN conversion, while Lava DL required implementation and training of a native SNN.
Table 7. Intel Accuracy
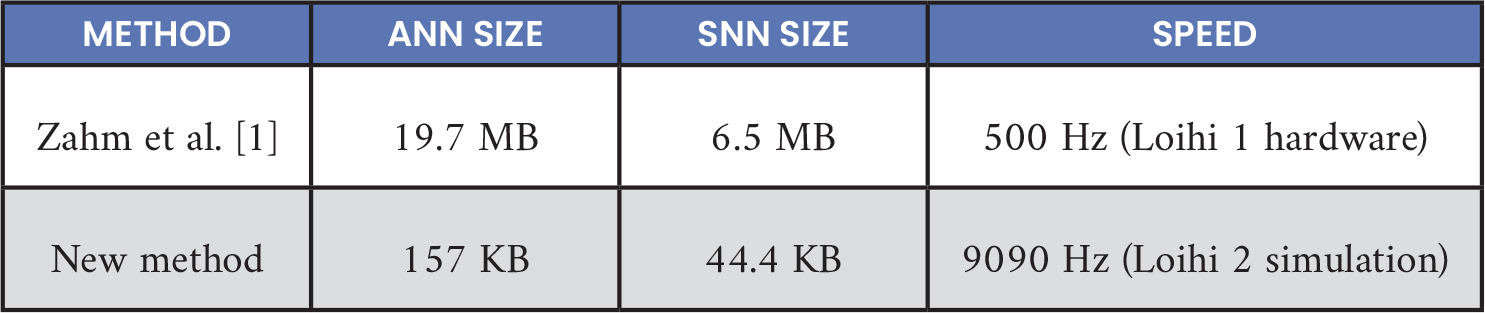
A 72.4% reduction in model size was observed between the full-precision ANN and the Lava DL model detailed in Table 8. With over 24 MB of memory available on Loihi 2 chips, this model is expected to comfortably fit on the hardware.
Table 8. ANN vs. Intel Size and Speed
While the Lava DL network could predict normal traffic 99% of the time, it struggled to accurately predict the precise class of non-normal traffic. The highest classification accuracy in non-normal traffic was 52% for DOS attacks.
Discussion
The following was presented from this work: an improved dataset with less normal traffic and improved ANN performance via better data preprocessing and hyperparameter tuning. For BrainChip, accuracy improved, model size decreased, and the model on the Akida chip was assessed for timing and power. Improvements were attributed to better data scaling and rigorous model quantization and retraining. For Intel, the performance of the new Lava DL framework was benchmarked, with a slight dip in performance compared to the prior SNN-Toolbox. However, accuracy was similar to BrainChip. Although the percentage of correct results (~98%) was like the state of the art presented in Gad et al. [2] and Sarhan et al. [3], low neuromorphic processors could be used with dramatic SWaP-C savings (see Table 1). In related work, a semi-supervised approach to cybersecurity on Intel’s Loihi 2 was investigated [8]. Testing these models on Intel hardware and larger and more diverse datasets is a goal for future work.
Conclusions
Because of their low SWaP-C envelope, neuromorphic technologies are well suited for deployable platforms such as manned aircraft or UAVs. Table 1 illustrates the SWaP-C advantages of neuromorphic processors compared to GPUs. Neuromorphic technologies could be used for cybersecurity of embedded networks or other functions like perception or control. Network traffic across CAN buses, for example, could be passed through neuromorphic processors. These processors would then detect abnormal traffic, which could then be blocked, preventing further harm.
Neuromorphic computing was also pursued for computer vision projects. Park et al. [9] used an ANN to SNN conversion to classify contraband materials across a variety of conditions, such as different temperatures, purities, and backgrounds. Neuromorphic technologies for image processing and automatic target recognition were also explored [10]. For image processing, hierarchical attention-oriented, region-based processing (HARP) [11] was used. HARP removes uninteresting image regions to speed up image transfer and subsequent processing. For automatic target recognition, U-net was used to detect tiny targets in infrared images in cluttered, varied scenes. U-net was run on Intel’s Loihi chip [12].
Research and development in cybersecurity and neuromorphic computing continues, with great potential in both.
Acknowledgments
This material is based upon work supported by the U.S. Department of Energy, Office of Science, Office of Advanced Scientific Computing Research program under Award Number DE-SC0021562."
Again it is difficult to imagine anything but a happy outcome from the Quantum Brainchip Phase 2 SBIR with the US Department of Energy.
My opinion only DYOR
Fact Finder
I know that some are always suspicious of opening links but I...







Add to My Watchlist
What is My Watchlist?
 (20min delay) (20min delay)
|
|||||
|
Last
20.8¢ |
Change
0.013(6.41%) |
Mkt cap ! $420.2M | |||
| Open | High | Low | Value | Volume |
| 19.5¢ | 21.8¢ | 19.5¢ | $1.919M | 9.196M |
Buyers (Bids)
| No. | Vol. | Price($) |
|---|---|---|
| 24 | 1222062 | 20.5¢ |
Sellers (Offers)
| Price($) | Vol. | No. |
|---|---|---|
| 21.0¢ | 819407 | 15 |
View Market Depth
| Last trade - 11.56am 01/07/2025 (20 minute delay) ? |
| BRN (ASX) Chart |